那么何为字节序(Endia)呢?
Big Endian是指低地址存放最高有效字节(MSB),而Little Endian则是低地址存放最低有效字节(LSB)。
大端模式
所谓的大端模式(Big-endian),是指数据的高字节,保存在内存的低地址中,而数据的低字节,保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
例子:
0000430: e684 6c4e 0100 1800 53ef 0100 0100 0000
0000440: b484 6c4e 004e ed00 0000 0000 0100 0000
在大端模式下,前32位应该这样读: e6 84 6c 4e ( 假设int占4个字节)
记忆方法: 地址的增长顺序与值的增长顺序相反
小端模式
所谓的小端模式(Little-endian),是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
例子:
0000430: e684 6c4e 0100 1800 53ef 0100 0100 0000
0000440: b484 6c4e 004e ed00 0000 0000 0100 0000
在小端模式下,前32位应该这样读: 4e 6c 84 e6( 假设int占4个字节)
记忆方法: 地址的增长顺序与值的增长顺序相同
有图有真相,举个例子,数字 0x12345678 在两种不同字节序CPU中的存储顺序如下图
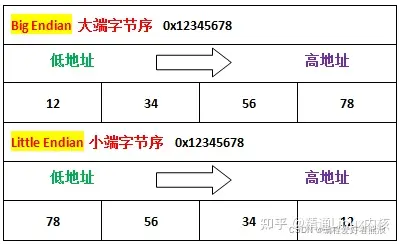
为什么会有这样的情况呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
Motorola的PowerPC系列CPU采用Big Endian方式存储数据。
Intel的x86系列CPU采用Little Endian方式存储数据。
ARM既可以工作在大端模式,也可以工作在小端模式。
再来说说,一些我所收集到的情况吧。
Windos(x86,x64)和Linux(x86,x64)都是Little Endian操作系统
在ARM上,我见到的都是用Little Endian方式存储数据。
C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的。
JAVA编写的程序则唯一采用Big Endian方式来存储数据。
所有网络协议也都是采用Big Endian的方式来传输数据的。所以有时我们也会把Big Endian方式称之为网络字节序。
【文章福利】 小编在群文件上传了一些个人觉得比较好得学习书籍、视频资料,有需要的可以进群【977878001】 领取!!!额外赠送一份价值699的内核资料包(含视频教程、电子书、实战项目及代码)
内核资料直通车: Linux内核源码技术学习路线+视频教程代码资料
学习直通车(腾讯课堂免费报名): Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
为什么要注意字节序的问题呢?
你可能这么问。当然,如果你写的程序只在单机环境下面运行,并且不和别人的程序打交道,那么你完全可以忽略字节序的存在。但是,如果你的程序要跟别人的程序产生交互呢?尤其是当你把你在微机上运算的结果运用到计算机群上去的话。在这里我想说说两种语言。C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而JAVA编写的程序则唯一采用big endian方式来存储数据。试想,如果你用C/C++语言在x86平台下编写的程序跟别人的JAVA程序互通时会产生什么结果?就拿上面的 0x12345678来说,你的程序传递给别人的一个数据,将指向0x12345678的指针传给了JAVA程序,由于JAVA采取big endian方式存储数据,很自然的它会将你的数据翻译为0x78563412。什么?竟然变成另外一个数字了?是的,就是这种后果。因此,在你的C程序传给JAVA程序之前有必要进行字节序的转换工作。
网络字节序
一、在进行网络通信时是否需要进行字节序转换? 相同字节序的平台在进行网络通信时可以不进行字节序转换,但是跨平台进行网络数据通信时必须进行字节序转换。
原因如下:网络协议规定接收到得第一个字节是高字节,存放到低地址,所以发送时会首先去低地址取数据的高字节。小端模式的多字节数据在存放时,低地址存放的是低字节,而被发送方网络协议函数发送时会首先去低地址取数据(想要取高字节,真正取得是低字节),接收方网络协议函数接收时会将接收到的第一个字节存放到低地址(想要接收高字节,真正接收的是低字节),所以最后双方都正确的收发了数据。而相同平台进行通信时,如果双方都进行转换最后虽然能够正确收发数据,但是所做的转换是没有意义的,造成资源的浪费。而不同平台进行通信时必须进行转换,不转换会造成错误的收发数据,字节序转换函数会根据当前平台的存储模式做出相应正确的转换,如果当前平台是大端,则直接返回不进行转换,如果当前平台是小端,会将接收到得网络字节序进行转换。
二、网络字节序 网络上传输的数据都是字节流,对于一个多字节数值,在进行网络传输的时候,先传递哪个字节?也就是说,当接收端收到第一个字节的时候,它将这个字节作为高位字节还是低位字节处理,是一个比较有意义的问题; UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节,也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节(即:高位字节存放在低地址处);由此可见,多字节数值在发送之前,在内存中因该是以大端法存放的; 所以说,网络字节序是大端字节序; 比如,我们经过网络发送整型数值0x12345678时,在80X86平台中,它是以小端发存放的,在发送之前需要使用系统提供的字节序转换函数htonl()将其转换成大端法存放的数值;
c# 大端转换 c#在windows平台上是小端字节序(Windos(x86,x64)和Linux(x86,x64)都是Little Endian操作系统,不止是c#)。网络发送字节流是按大端序发送,也就是从左到右发送,和c#的小端序相反,造成网关不能正常识别协议。所以需要转换
大小端转换
int x = 439041118; // 十六进制为 1A2B3C5E
string s = null;
byte[] b = BitConverter.GetBytes( x );
s = BitConverter.ToString( b ); // 小端模式
Console.WriteLine( s ); // 小端输出 为 5E-3C-2B-1A
Array.Reverse( b ); // 反转
s = BitConverter.ToString( b ); // 大端模式
Console.WriteLine( "{0:x}", s ); // 大端输出 为 1A-2B-3C-5E
Console.ReadKey();
C# 判断数据在此计算机结构中存储时的字节顺序(“Endian”性质),即大端还是小端
int data = 439041118; // 十六进制为 1A2B3C5E
byte[] bData = BitConverter.GetBytes( data );
if (BitConverter.IsLittleEndian) // 若为 小端模式
{
Array.Reverse( bData ); // 转换为 大端模式
}
string s = BitConverter.ToString( bData );
Console.WriteLine(s);
Console.ReadKey();
一些封装
//翻转byte数组
public static void ReverseBytes(byte[] bytes)
{
byte tmp;
int len = bytes.Length;
for (int i = 0; i < len / 2; i++ )
{
tmp = bytes[len - 1 - i];
bytes[len - 1 - i] = bytes[i];
bytes[i] = tmp;
}
}
//规定转换起始位置和长度
public static void ReverseBytes(byte[] bytes, int start, int len)
{
int end = start + len - 1;
byte tmp;
int i = 0;
for (int index = start; index < start + len/2; index++,i++)
{
tmp = bytes[end - i];
bytes[end - i] = bytes[index];
bytes[index] = tmp;
}
}
// 翻转字节顺序 (16-bit)
public static UInt16 ReverseBytes(UInt16 value)
{
return (UInt16)((value & 0xFFU) << 8 | (value & 0xFF00U) >> 8);
}
// 翻转字节顺序 (32-bit)
public static UInt32 ReverseBytes(UInt32 value)
{
return (value & 0x000000FFU) << 24 | (value & 0x0000FF00U) << 8 |
(value & 0x00FF0000U) >> 8 | (value & 0xFF000000U) >> 24;
}
// 翻转字节顺序 (64-bit)
public static UInt64 ReverseBytes(UInt64 value)
{
return (value & 0x00000000000000FFUL) << 56 | (value & 0x000000000000FF00UL) << 40 |
(value & 0x0000000000FF0000UL) << 24 | (value & 0x00000000FF000000UL) << 8 |
(value & 0x000000FF00000000UL) >> 8 | (value & 0x0000FF0000000000UL) >> 24 |
(value & 0x00FF000000000000UL) >> 40 | (value & 0xFF00000000000000UL) >> 56;
}
另外c#直接提供了网络字节序转换方法。
System.Net.IPAddress.HostToNetworkOrder(本机到网络转换)
System.Net.IPAddress.NetworkToHostOrder(网络字节转成本机)
推荐使用这种方法,简单有效。
short x = 6;
short b = System.Net.IPAddress.HostToNetworkOrder(x); //把x转成相应的大端字节数
byte[] bb = System.BitConverter.GetBytes(b);//这样直接取到的就是大端字节序字节数组。
对于字符串型:
使用 System.Text.Encoding.Default.GetBytes();直接取字串对应字节数组。
不知道为什么这个方法取到的直接就是大端字节数组。不用转换。
后来查了一下,关于字串的字节序问题,因为gbk和utf-8都是以单个字节表示数字的,所以不存在字节序问题,在多个不同系统架构都用。对于utf-16,则是以双字节表示一个整数,所以为会有字节序问题,分大小端unicode。
System.Text.Encoding.Default.GetBytes();在我的简体中文系统上是以gb2312的编码,也就是单个字来进行编码的,所以也不会有字节序问题。
补充:“对于任何字符编码,编码单元的顺序是由编码方案指定的,与endian无关。例如GBK的编码单元是字节,用两个字节表示一个汉字。这两个字节的顺序是固定的,不受CPU字节序的影响。UTF-16的编码单元是word(双字节),word之间的顺序是编码方案指定的,word内部的字节排列才会受到endian的影响。”,
所以utf-8也没有字节序的问题。字节序问题之存在于需要使用两个字节以上来表示整数。而UTF-8只是一串字节流,不存在字节序问题,不过将这些字节流翻译成Unicode比其他的传输方式复杂。以字节为单位编码的,无论一个汉字是多少个字节,都无字节序问题。
你注意,字节序问题不是指多个字节传输的先后,这个是固定的无异议的。而是指一个多字节编码在机器中的表示方式问题。 char str[] = “abaksdkakskasklasflk”;
这个无字节序问题。但 int str[] = {0x11223344, 2, 3 }
就有字节序问题了。因为str[0]同样数值不同机器中表示不同。
而剩下的, 就是字符编码内部的字节序了。比如UTF-16是用两个字节表示一个字符,但是这两个字节内部如何排序,系统并不知道,所以必须指定字节序。但是UTF-8由于几个字节表示并不相同,一定要从那个表示长度的字节开始读,相当于一开始就知道该从哪里是队头队尾,所以不存在字节序问题。
原文作者:极致Linux内核
原文地址:https://zhuanlan.zhihu.com/p/577630751(版权归原文作者所有,侵权联系删除)
